不止一次有同学在 Issues、邮件等渠道中向我反馈增加站内搜索功能。本来准备什么时候搞个 2.0 版的主题再加上这些新功能,可一直没什么太好的想法,反正也是折腾,就把搜索功能做了一下。
搜索方案
针对无数据库的静态博客搜索方案一般有两种:
- 第三方搜索服务;
- 序列化站点内容作为数据源,然后自己写查询方法。
第三方搜索服务
基于搜索引擎的
包括 Google 和百度提供的站内搜索,比如 Hexo 文档中的辅助函数 search-form 就提供了一个 Google 搜索框。搜索结果取决于该搜索引擎对你站点的收录情况。
抛开其他原因来讲,没有颜值的搜索服务我是不会考虑的。
接着我实验了一下在 Hexo 中有用户基础的 Swiftype 和 Hexo 官网使用的 Algolia。
Swiftype
Swiftype 安装很简单,关于其在 Hexo 中使用的文章介绍也很多,我只说下使用体验。
配合我自定义的搜索框样式,外观展现还算过关。
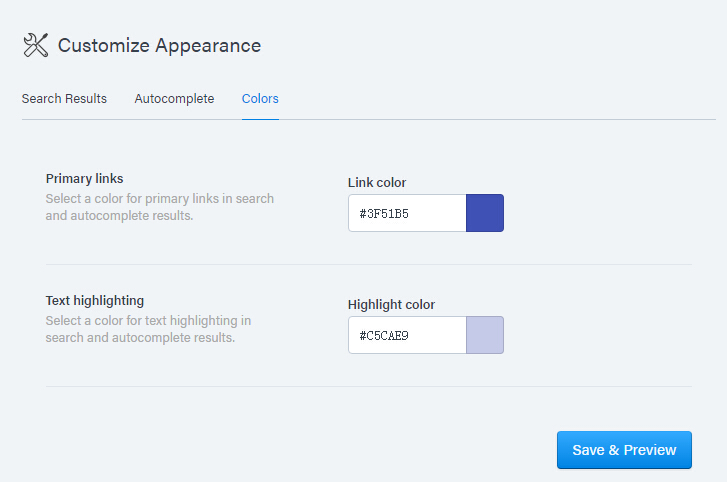
可以对色调进行修改,由于是在单页面展示搜索结果,就算不提供外观修改也可以自己重写 css ,类似多说。
Swiftype-colors
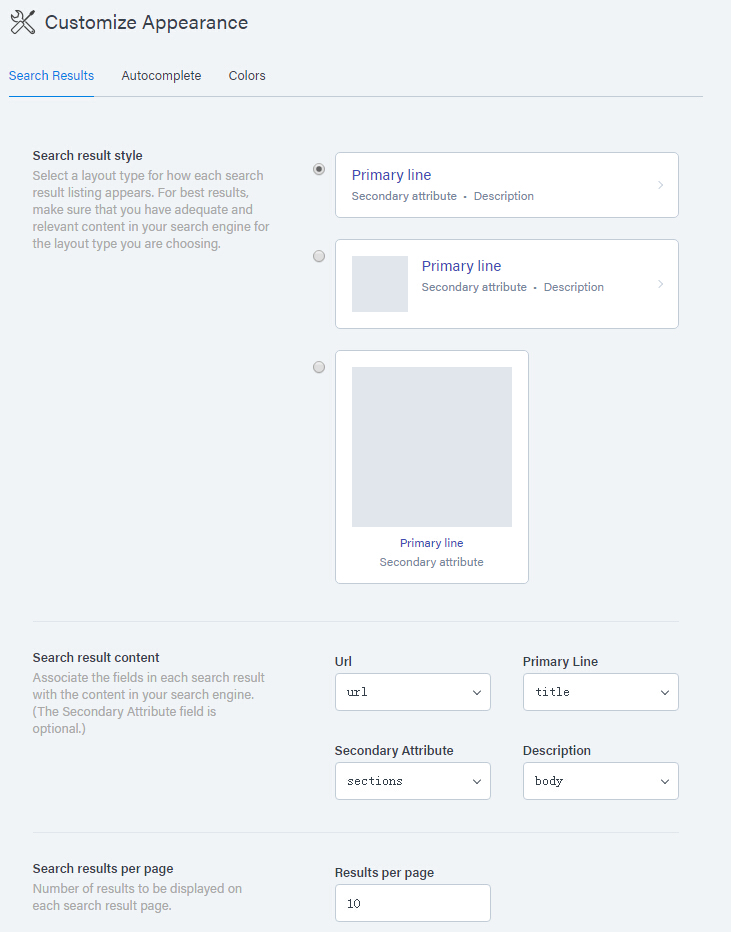
搜索结果的展示可以自定义,包括内容布局、字段排列、分页等。
Swiftype-results
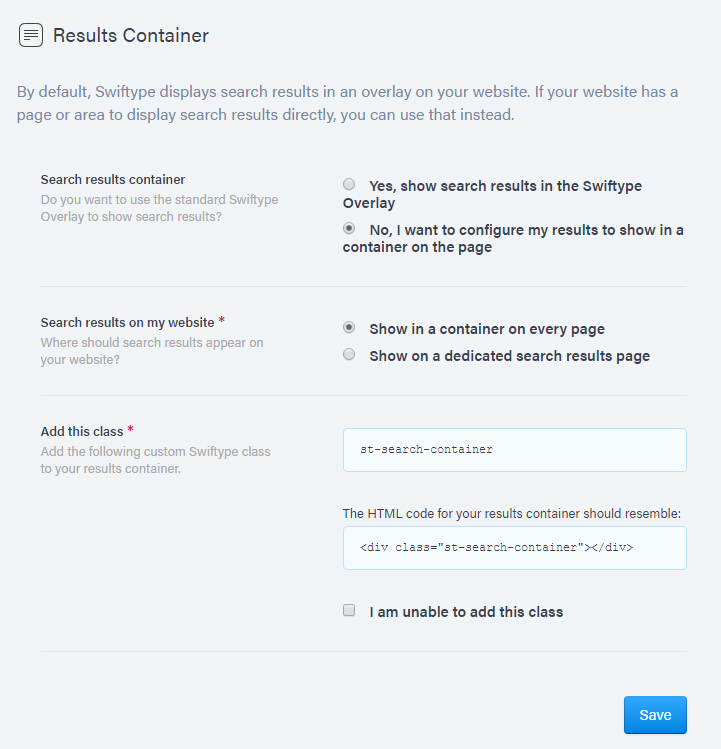
搜索结果容器可完全自定义,可设置单页或新页面显示搜索结果,对外观的控制力更强。
Swiftype-container
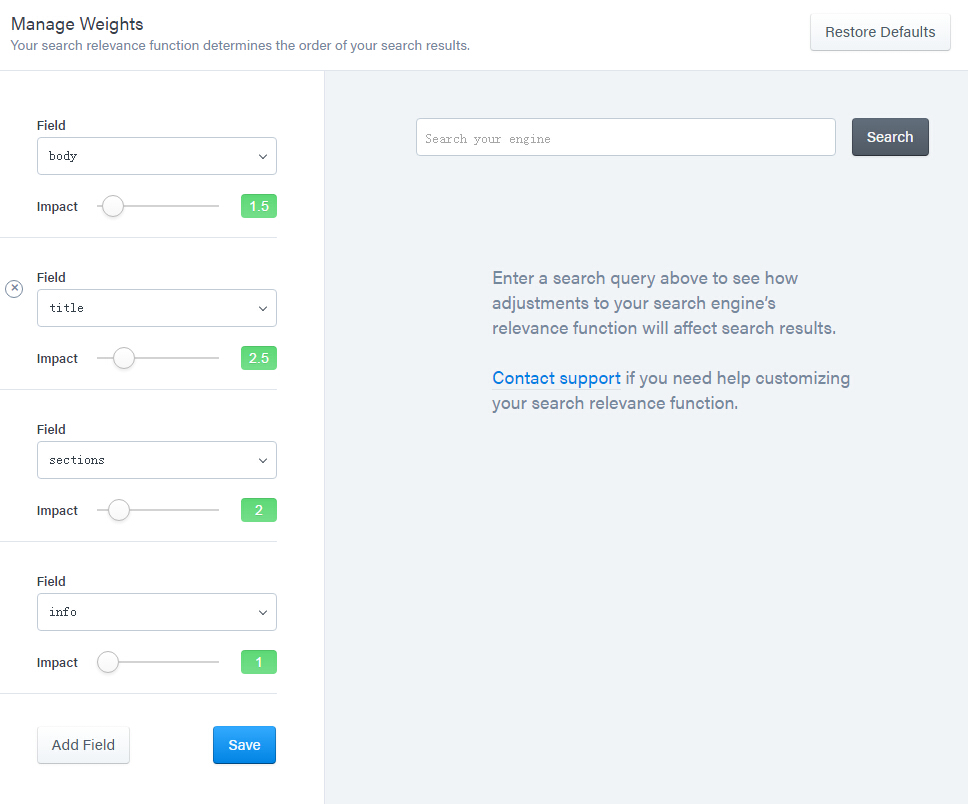
可以设置字段权重,比如优先展示文章标题的匹配结果。
Swiftype-sort
可以单独为某个关键字搜索结果进行管理,比如排序、置顶、删除等等,话说某度推广不就是这样吗。
Swiftype-rank
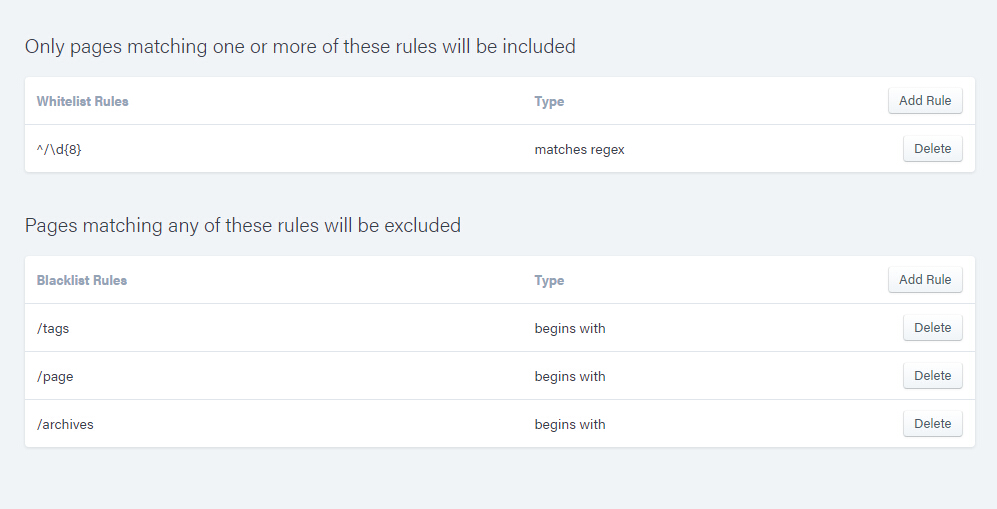
可以设置抓取规则,比如只抓取文章页。
Swiftype-rules
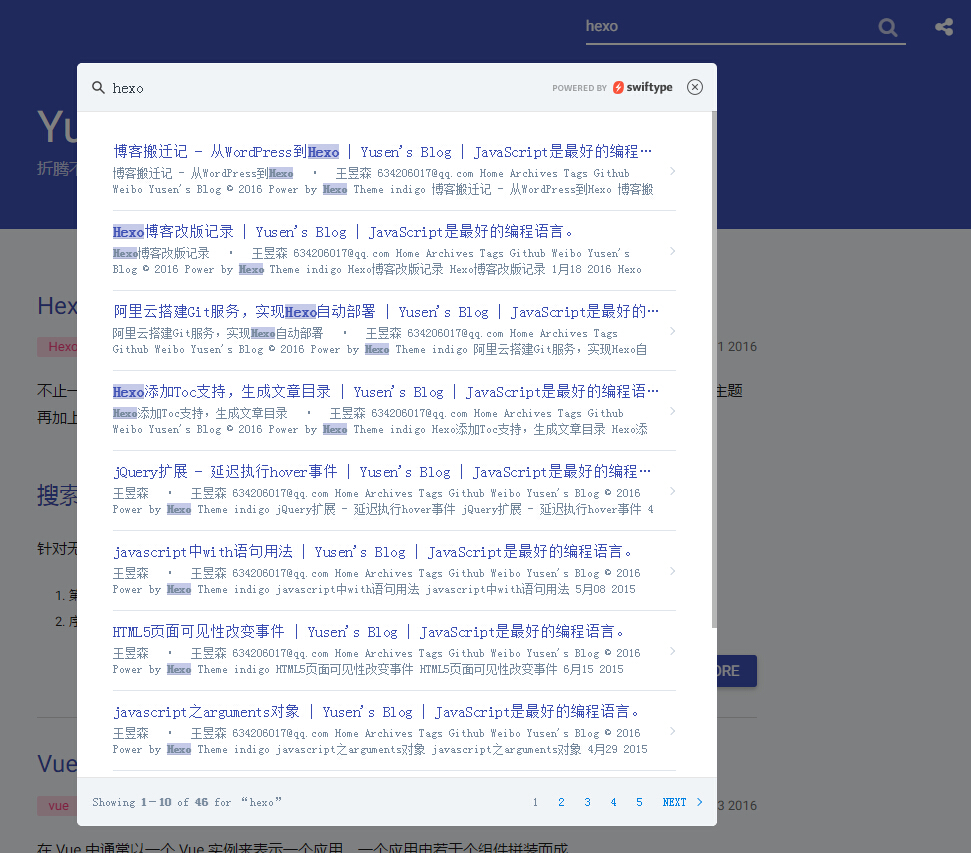
默认的字段匹配不满意,下图是对hexo的搜索结果。Swiftype 的body字段默认抓取整个页面,我每个页面的左侧 footer 都有hexo这个单词,在我设置了只抓取文章页后,博客一共 46 篇文章也就匹配了 46 个结果。我期望它只对文章内容检索,这样更精准。
Swiftype-show
如果能自定义抓取字段,指定抓取内容当然是极好的。Swiftype 文档中也提供了这方面内容,Crawler。
大概看了一下,感觉 Content Inclusion/Exclusion 和 Meta Tags 方式应该能满足需求。我也尝试了一下,发现没效果,不知道是不是要重新抓取才生效。
设置重新抓取后等了 1 个小时还没什么效果,我只好先进行下一步了。
Algolia
Algolia 我只注册了账户,然后就没有然后了。。。因为我准备使用方案2了。
从 Algolia 管理界面和文档上来看不会比 Swiftype 差,可留作备选。
自定义搜索
没有数据库的前提下实现查询,也可以使用数据文件做数据源。Hexo 中也有这方面的先驱者,在 Hexo-Plugins 页可以找到生成数据文件的两个插件,hexo-generator-json-content 和 hexo-generator-search。
hexo-generator-json-content 生成的数据文件为json格式。
meta: { title: hexo.config.title, subtitle: hexo.config.subtitle, description: hexo.config.description, author: hexo.config.author, url: hexo.config.url }, pages: [{ title: page.title, slug: page.slug, date: page.date, updated: page.updated, comments: page.comments, permalink: page.permalink, path: page.path, excerpt: page.excerpt, keywords: null text: page.content, raw: page.raw, content: page.content }], posts: [{ title: post.title, slug: post.slug, date: post.date, updated: post.updated, comments: post.comments, permalink: post.permalink, path: post.path, excerpt: post.excerpt, keywords: null text: post.content, raw: post.raw, content: post.content, categories: [{ name: category.name, slug: category.slug, permalink: category.permalink }], tags: [{ name: tag.name, slug: tag.slug, permalink: tag.permalink }] }]
|
hexo-generator-search 生成的数据文件为xml格式。
<search> <entry> <title>Post title</title> <url>http://yourposturl.html</url> <content type="html">helloworldhelloworldhelloworldhelloworldhelloworldhelloworld</content> </entry> <entry> <title>Post title</title> <url>http://yourposturl.html</url> <content type="html">helloworldhelloworldhelloworldhelloworldhelloworldhelloworld</content> </entry> </search>
|
对于 js 语言来说还是解析 json 更方便,如果需要用xml做数据文件我完全可以使用已有的atom.xml。
hexo-generator-json-content 生成的json数据内容挺全的,不过并不是我都需要的。可以通过添加站点配置设置你需要生成的字段。
meta是站点信息,pages是除文章页以外的页面信息,这都是我不需要的,我只要求搜索文章页。
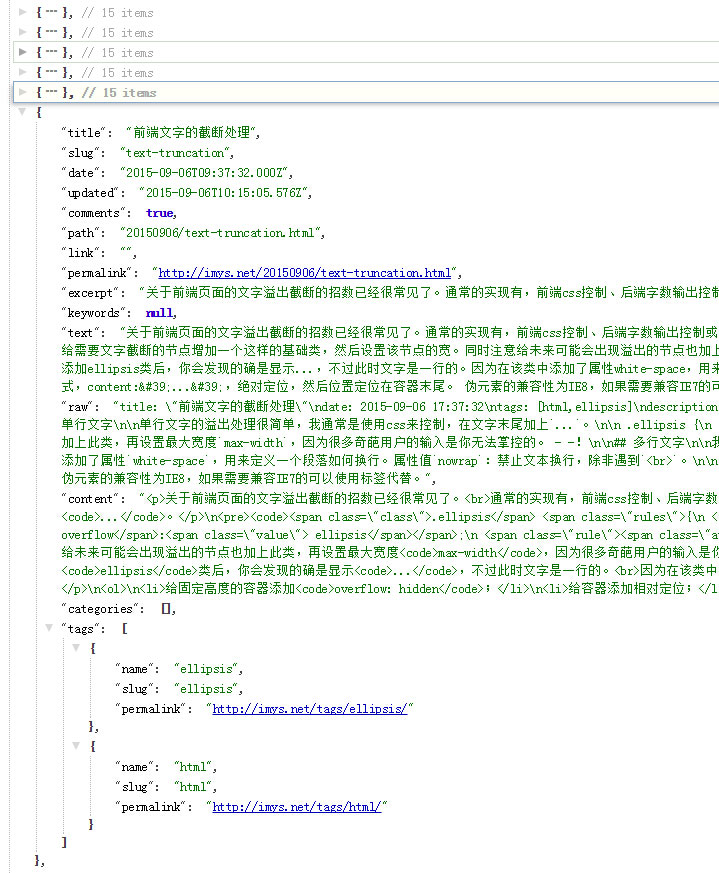
此外,文章页的字段也可以根据需求减少,以减小数据文件大小。下图可以直观看出每个字段表示的内容。
hexo-generator-json-content
slug、comments、link、keywords、categories都是无内容或不需要的字段;date和updated、path和permalink留其一即可;excerpt可以不要,因为我们要检索文章全文;raw是markdown元数据,content是包含html标签的文章内容,处理起来最方便的是text纯文本。
最后的配置如下,需要放到hexo/_config.yml中。
jsonContent: meta: false pages: false posts: title: true date: true path: true text: true raw: false content: false slug: false updated: false comments: false link: false permalink: false excerpt: false categories: false tags: true
|
接着就是实现查询方法并把结果渲染到页面。
function loadData(callback) { } function matcher(post, regExp) { return regExp.test(post.title) || post.tags.some(function(tag) { return regExp.test(tag.name); }) || regExp.test(post.text); } function render(data) { } function search(key) { var regExp = new RegExp(key.replace(/[ ]/g, '|'), 'gmi'); loadData(function(data) { var result = data.filter(function(post) { return matcher(post, regExp); }); render(result); }); }
|
正则加上filter、some两个数组过滤函数,就这么简单。也没想做太复杂,否则匹配结果高亮、匹配片段截取又够折腾半天。
完成后就是现在博客的搜索了,PC 端浮动面板显示,Mobile 端全屏显示。