最近有朋友找我帮他下载歌曲,果然在其他人眼里,程序员简直是“无所不能”的存在啊。
不过,这个需求对于程序员来讲,还算是比较正常的,比那些找你“刷QB”、“盗号”什么的强多了。
要是放到以前下载歌曲,直接回一句“搜百度”完事,近年来歌曲版权逐渐被重视了,一些歌曲逐渐变为会员下载或者收费下载。不过好歹还是可以在线播放的,只要能播放,那想找到歌曲文件就很简单了。
可以从开发者工具 - Network 里找音乐文件的请求链接,或者打开浏览器本地缓存文件夹找大文件。
为了防止以后有朋友发出重复需求,我决定写一个工具出来。
这其中涉及到了跨域访问、页面内容抓取,最终决定用express和cheerio来搞,服务端不存在跨域问题。
试了一些音乐网站的歌曲搜索和播放后,最终把目标瞄准了酷我音乐。
搜索
酷我的歌曲搜索就是一个表单提交,页面跳转,服务端直接输出一个包含搜索结果的页面,这个页面的 URL 包含了查询字符串。
http://sou.kuwo.cn/ws/NSearch?type=music&key=曾经的你
字段type表示搜索类型,也就是该页面上的 7 个标签页。
对应关系如下:
all --综合 artist --歌手 music --歌曲 album --专辑 mv --MV playlist --歌单 lyric --歌词
|
对于目前的需求来说,type=music已经足够了。
key是搜索关键字。该页签下还有一个参数pn表示页数,每页最多显示 25 项,该参数省略表示第一页。
该页面的搜索列表和分页均为后端直出,想要封装自己的接口只好获取整个页面内容,然后解析 DOM ,组成自己需要的数据。
模版
views/index.html
<input type="text" id="key" value="曾经的你"><button id="search">搜索</button> <hr> <ol id="list"></ol> <hr> <div id="page"></div> <script src="http://apps.bdimg.com/libs/jquery/1.9.0/jquery.min.js"></script>
|
模版使用的 ejs。
路由
app.get('/', function(req, res) { res.render('index', { title: 'Music' }); }); app.get('/search/:key/:pn', function(req, res) { });
|
实现
逻辑很简单,点击搜索时取文本框的值 ajax 请求/search/:key/:pn获取数据渲染#list和#page。
(function () { var $key = $('#key'), $so = $('#search'), $list = $('#list'), $page = $('#page'); function getData(key, pn) { $.getJSON('/search/' + key + '/' + pn, function(data) { }); } function search() { var key = $.trim($key.val()); if(!key) { return; } getData(key, 1); } $so.click(function () { search(); }); $key.keyup(function(event) { if(event.keyCode === 13) { search(); } }); }.call(this));
|
根据前端的需求,后端输出的数据格式应该是这样的。
开始封装对应格式的数据。
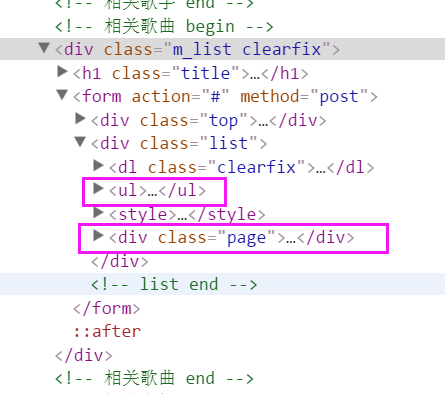
通过开发者工具 - Elements 可以找到酷我搜索结果页面的列表和分页的 Dom。可以使用 http 模块去请求这个页面,拿到整个页面文档,使用 cheerio 选取对应的 Dom 来组装成我们需要的数据。
相关Dom
歌曲列表的选择器为.m_list ul,分页的选择器为.page。
当然,使用类选择器时要确定该类在页面内是唯一的。
app.get('/search/:key/:pn', function(req, res) { var key = req.params.key, pn = req.params.pn, option = { host: 'sou.kuwo.cn', port: 80, path: '/ws/NSearch?' + querystring.stringify({ type: 'music', key: key, pn: pn }), method: 'GET' }; var req2 = http.request(option, function(res2) { var body = ''; res2.setEncoding('utf8'); res2.on('data', function(data) { body += data; }); res2.on('end', function() { var $ = cheerio.load(body), $list = $('.m_list ul li'), $page = $('.page'), list = []; $list.each(function(i, el) { var $this = $(el); list.push({ id: parseInt($this.find('input[name="musicNum"]').val()), name: $this.find('.m_name a').attr('title'), album: $this.find('.a_name a').attr('title'), singer: $this.find('.s_name a').attr('title') }); }); $page.find('a').each(function(i, el) { var $this = $(el), href = $this.attr('href'); if (href !== '#@') { var num = href.split('=').reverse()[0]; $this.attr('data-option', JSON.stringify({ key: key, pn: num })); } $this.attr('href', 'javascript:;'); }); res.send({ page: $page.html(), list: list }); }); }); req2.on('error', function(e) { console.log(e); }); req2.end(); });
|
歌曲的数据项取了 id、歌名、专辑、歌手。
分页的 Dom 结构比较简单,我直接把分页内的a:href属性替换了,添加自定义数据用于前端点击重渲染,直接返回整个分页的 HTML。
以上代码引用的模块有http、querystring、cheerio。
不得不说cheerio用来爬页面实在是太棒了!
以上代码在一个请求处理逻辑中又发出 http 请求,显然可以封装出一个请求模块,以备其他地方使用。
lib/request.js
var http = require('http'); module.exports = function(options) { return new Promise(function(resolve, reject) { var req = http.request(options, function(res) { var body = ''; res.setEncoding('utf8'); res.on('data', function(data) { body += data; }); res.on('end', function() { resolve(body); }); }); req.on('error', function(e) { reject(e); }); req.end(); }); }
|
添加一个 request 模块用于 http 请求,以 Promise 方式返回。
这样搜索的处理逻辑代码就变成这样。
app.get('/search/:key/:pn', function(req, res) { var key = req.params.key, pn = req.params.pn, option = { host: 'sou.kuwo.cn', port: 80, path: '/ws/NSearch?' + querystring.stringify({ type: 'music', key: key, pn: pn }), method: 'GET' }; request(option).then(function(body) { var $ = cheerio.load(body), $list = $('.m_list ul li'), $page = $('.page'), list = []; $list.each(function(i, el) { var $this = $(el); list.push({ id: parseInt($this.find('input[name="musicNum"]').val()), name: $this.find('.m_name a').attr('title'), album: $this.find('.a_name a').attr('title'), singer: $this.find('.s_name a').attr('title') }); }); $page.find('a').each(function(i, el) { var $this = $(el), href = $this.attr('href'); if (href !== '#@') { var num = href.split('=').reverse()[0]; $this.attr('data-option', JSON.stringify({ key: key, pn: num })); } $this.attr('href', 'javascript:;'); }); res.send({ page: $page.html(), list: list }); }, function(e) { console.log(e); }); });
|
数据有了,开始写前端页面渲染部分。
function getData(key, pn) { $.getJSON('/search/' + key + '/' + pn, function(data) { var body = ''; data.list.forEach(function (v, i) { body +='<li><a href="download/'+ v.id +'">'+ v.name +' '+ v.album +' '+ v.singer +'</a></li>'; }); $list.html(body); $page.html(data.page); }); }
|
每次调用这个方法都会获取数据渲染列表和分页。
歌曲列表的每一项直接使用了 a 链接,点击直接下载歌曲,会有一个新的路由/download/:id。
分页内的 a 链接已经加上了自定义数据,直接添加点击事件拿到数据调用getData方法。
$page.on('click', 'a[data-option]', function () { var option = $(this).data('option'); getData(option.key, option.pn); });
|
至此,搜索加分页就全部完成了。
下载
在酷我的页面中点击歌曲名可以跳转到一个歌曲播放页,该页面 URL 格式为http://www.kuwo.cn/yinyue/100062/,其中的 100062 就是歌曲ID了。
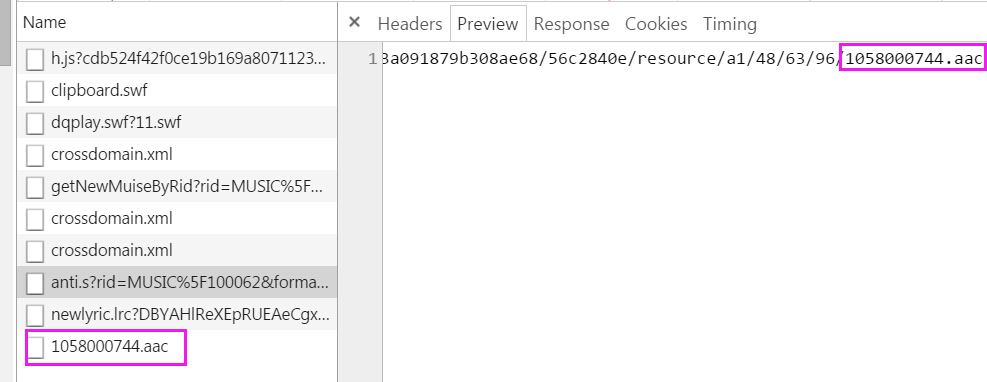
对于资源文件,直接分析 Network,找到资源文件请求和歌曲ID之间的关系,期望可以直接获取到资源文件的链接。
酷我Network
最终分析结果:
ID100062 的资源文件名是 1058000744.aac。
有一个请求 http://antiserver.kuwo.cn/anti.s?rid=MUSIC_100062&format=aac|mp3&type=convert_url&response=url 的结果为 http://win.web.ra03.sycdn.kuwo.cn/07baab80f0a6dd9b3a091879b308ae68/56c2840e/resource/a1/48/63/96/1058000744.aac。
这样我们直接用歌曲ID去请求http://antiserver.kuwo.cn/anti.s就能获得歌曲链接了。
酷我的默认请求为.aac格式,应该是和参数format=aac|mp3有关,可以改成format=mp3|aac。
app.get('/download/:id', function(req, res) { var option = { host: 'antiserver.kuwo.cn', port: 80, path: '/anti.s?rid=MUSIC_' + req.params.id + '&format=mp3|aac&type=convert_url&response=url', method: 'GET' }; request(option).then(function(body) { res.redirect(body); }, function(e) { console.log(e); }); });
|
request 模块又派上用场了,由于该请求直接返回了歌曲链接,我就直接重定向到该链接了。
为了使歌曲在新窗口打开,前端页面列表项中的 a 链接要添加target="_blank"。
成果展示
截图
DownloadMusic
Code
Github - DownloadMusic